
PiecewiseLeakyRelu#
- class braintools.surrogate.PiecewiseLeakyRelu(c=0.01, w=1.0)#
Judge spiking state with a piecewise leaky relu function.
The forward function:
\[\begin{split}g(x) = \begin{cases} 1, & x \geq 0 \\ 0, & x < 0 \\ \end{cases}\end{split}\]The original function:
\[\begin{split}\begin{split}g(x) = \begin{cases} cx + cw, & x < -w \\ \frac{1}{2w}x + \frac{1}{2}, & -w \leq x \leq w \\ cx - cw + 1, & x > w \\ \end{cases}\end{split}\end{split}\]Backward function:
\[\begin{split}\begin{split}g'(x) = \begin{cases} \frac{1}{w}, & |x| \leq w \\ c, & |x| > w \end{cases}\end{split}\end{split}\]- Parameters:
See also
piecewise_leaky_reluFunction version of this class.
Examples
>>> import braintools >>> import brainstate >>> import jax.numpy as jnp >>> >>> # Create a piecewise leaky ReLU surrogate >>> plr_fn = braintools.surrogate.PiecewiseLeakyRelu(c=0.01, w=1.0) >>> >>> # Apply to input >>> x = jnp.array([-2.0, -0.5, 0.0, 0.5, 2.0]) >>> spikes = plr_fn(x) >>> print(spikes) # [0., 0., 1., 1., 1.]
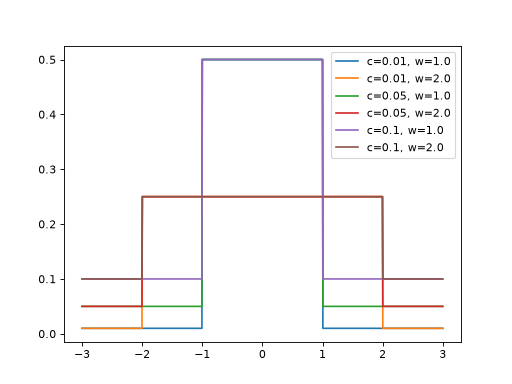
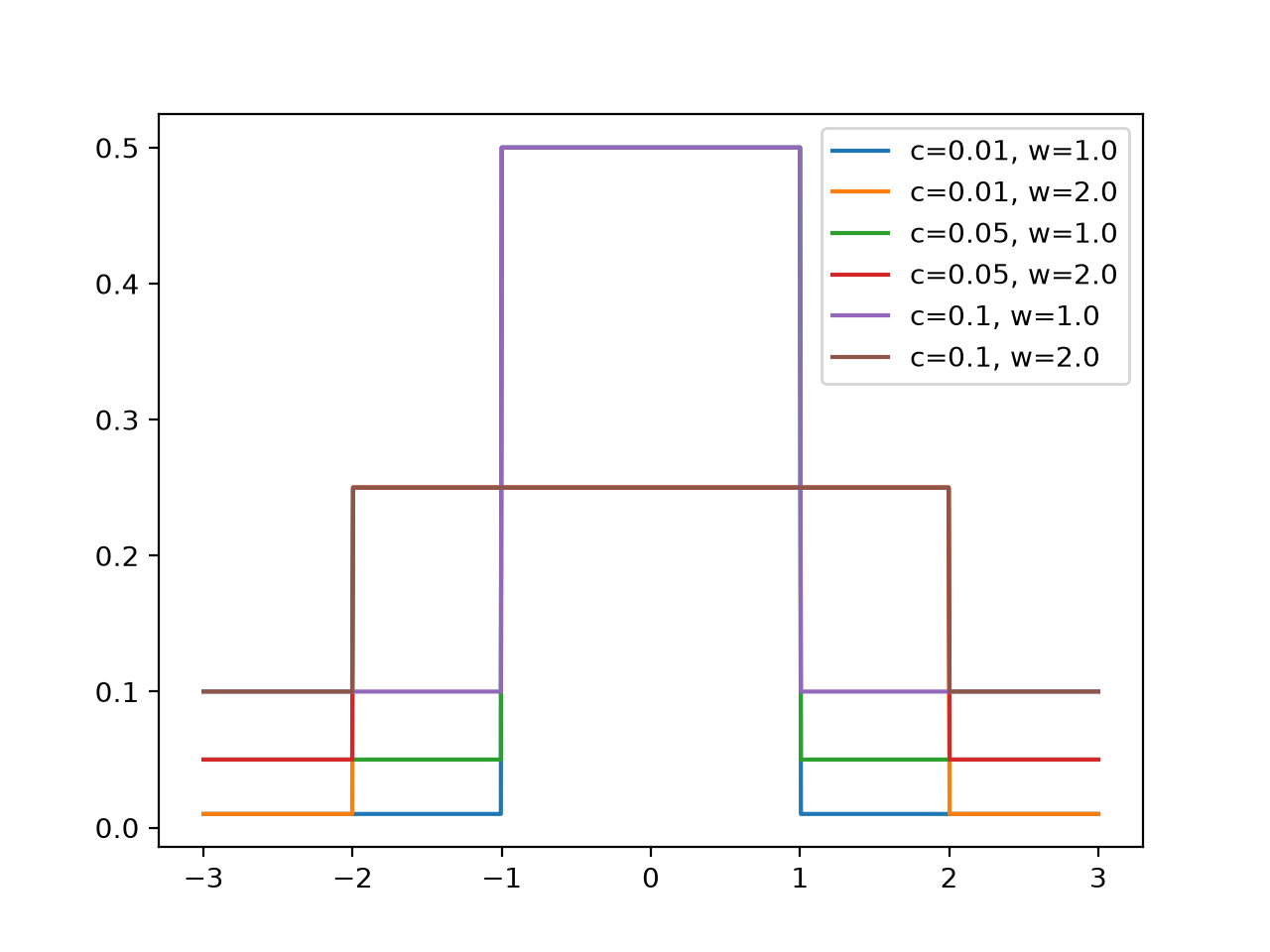
>>> import jax >>> import braintools >>> import brainstate as brainstate >>> import matplotlib.pyplot as plt >>> xs = jax.numpy.linspace(-3, 3, 1000) >>> for c in [0.01, 0.05, 0.1]: >>> for w in [1., 2.]: >>> plr_fn = braintools.surrogate.PiecewiseLeakyRelu(c=c, w=w) >>> grads = brainstate.augment.vector_grad(plr_fn)(xs) >>> plt.plot(xs, grads, label=f'c={c}, w={w}') >>> plt.legend() >>> plt.show()
(
Source code,png,hires.png,pdf)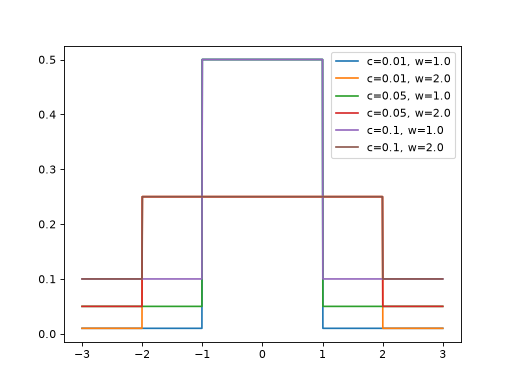
Notes
This surrogate provides a leaky gradient outside the window [-w, w], which can help with gradient flow in deep networks while maintaining a strong gradient near the threshold.
References
{kind=link}
{kind=link}