
PiecewiseQuadratic#
- class braintools.surrogate.PiecewiseQuadratic(alpha=1.0)#
Judge spiking state with a piecewise quadratic function.
This class implements a surrogate gradient method using a piecewise quadratic function for training spiking neural networks. It provides smooth gradients within a defined range around zero.
- Parameters:
alpha (
float) – A parameter controlling the width and steepness of the surrogate gradient. Higher values result in a narrower gradient window. Default is 1.0.
See also
piecewise_quadraticFunction version of this class.
Examples
>>> import braintools >>> import brainstate >>> import jax.numpy as jnp >>> >>> # Create a piecewise quadratic surrogate gradient function >>> pq_fn = braintools.surrogate.PiecewiseQuadratic(alpha=1.0) >>> >>> # Apply to membrane potentials >>> x = jnp.array([-2.0, -0.5, 0.0, 0.5, 2.0]) >>> spikes = pq_fn(x) >>> print(spikes) # Binary spike output: [0., 0., 1., 1., 1.] >>> >>> # Use in a spiking neural network >>> import brainstate.nn as nn >>> >>> class SpikingNeuron(nn.Module): ... def __init__(self): ... super().__init__() ... self.spike_fn = braintools.surrogate.PiecewiseQuadratic(alpha=2.0) ... self.membrane = 0.0 ... ... def forward(self, input_current): ... self.membrane += input_current ... spike = self.spike_fn(self.membrane) ... self.membrane = self.membrane * (1 - spike) # Reset on spike ... return spike
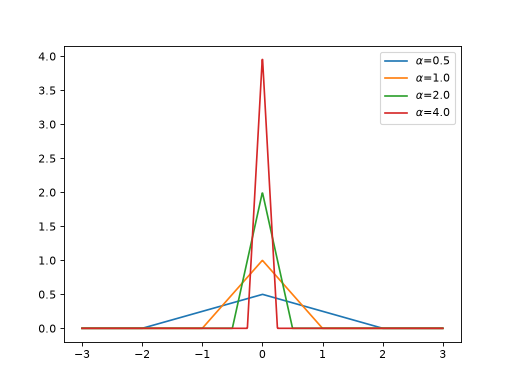
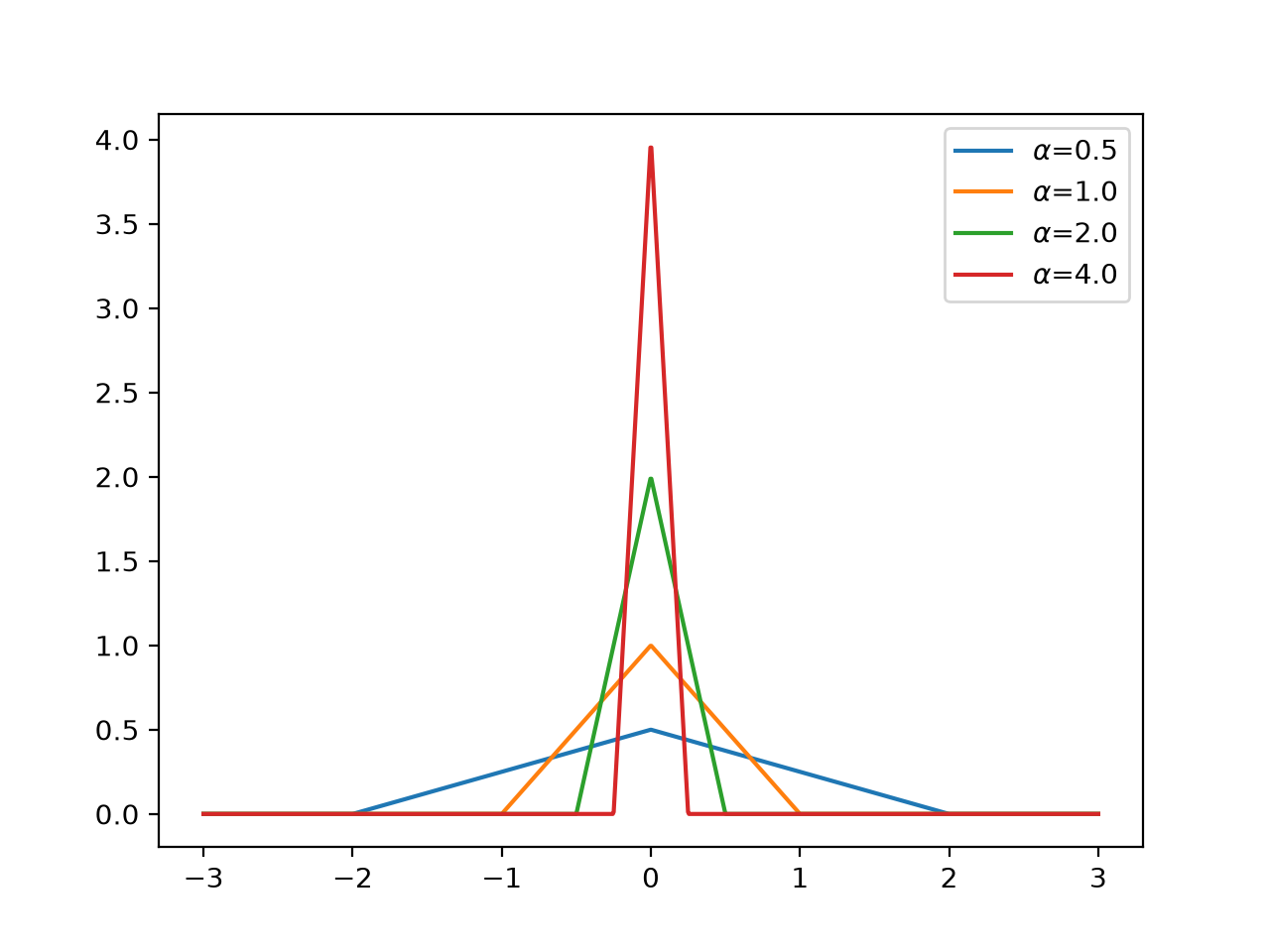
>>> import jax >>> import braintools >>> import brainstate as brainstate >>> import matplotlib.pyplot as plt >>> xs = jax.numpy.linspace(-3, 3, 1000) >>> for alpha in [0.5, 1., 2., 4.]: >>> pq_fn = braintools.surrogate.PiecewiseQuadratic(alpha=alpha) >>> grads = brainstate.augment.vector_grad(pq_fn)(xs) >>> plt.plot(xs, grads, label=r'$\alpha$=' + str(alpha)) >>> plt.legend() >>> plt.show()
(
Source code,png,hires.png,pdf)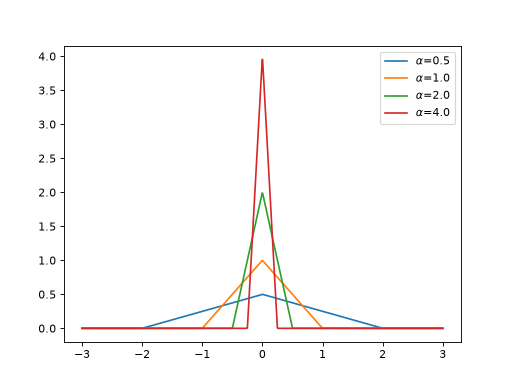
Notes
The forward pass uses a Heaviside step function (1 for x >= 0, 0 for x < 0), while the backward pass uses a piecewise quadratic surrogate gradient.
The surrogate gradient is non-zero only within the range \([-1/\\alpha, 1/\\alpha]\), providing localized gradient flow during backpropagation. This helps prevent gradient explosion and vanishing gradients in deep spiking networks.
The surrogate gradient is defined as:
\[\begin{split}g'(x) = \\begin{cases} 0, & |x| > \\frac{1}{\\alpha} \\\\ -\\alpha^2|x| + \\alpha, & |x| \\leq \\frac{1}{\\alpha} \\end{cases}\end{split}\]References
{kind=link}
{kind=link}