
ReluGrad#
- class braintools.surrogate.ReluGrad(alpha=0.3, width=1.0)#
Judge spiking state with the ReLU gradient function [1].
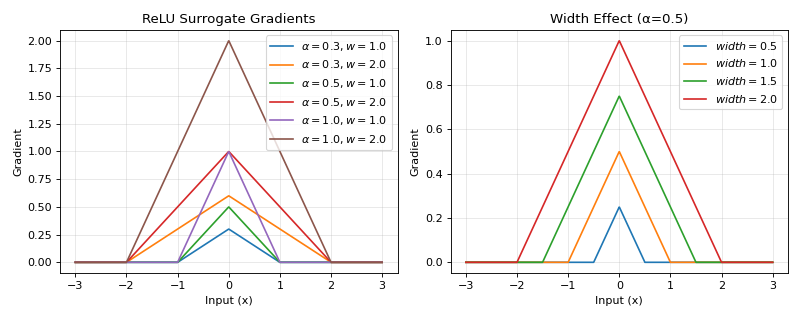
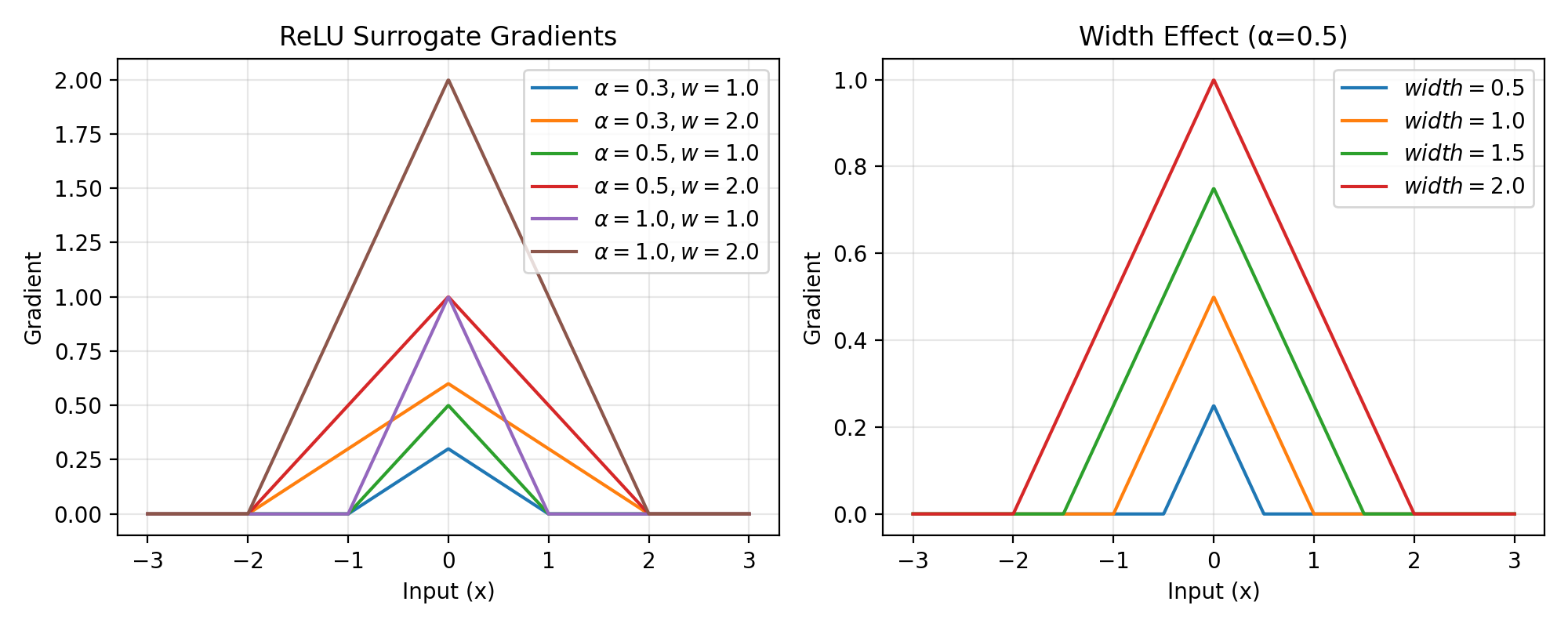
The ReLU gradient surrogate provides a triangular-shaped gradient function with finite support. It creates a linear decrease from the center to the edges, providing a simple and computationally efficient gradient that is non-zero only within a specified width around zero.
The forward function:
\[\begin{split}g(x) = \begin{cases} 1, & x \geq 0 \\ 0, & x < 0 \\ \end{cases}\end{split}\]Backward gradient:
\[g'(x) = \text{ReLU}(\alpha * (\text{width} - |x|)) = \max(0, \alpha * (\text{width} - |x|))\]This creates a triangular gradient centered at x=0 with:
Peak value: α × width at x=0
Linear decrease to 0 at x=±width
Zero gradient for |x| > width
>>> import jax >>> import jax.numpy as jnp >>> import brainstate >>> import braintools.surrogate as surrogate >>> import matplotlib.pyplot as plt >>> >>> xs = jnp.linspace(-3, 3, 1000) >>> fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4)) >>> >>> # Plot gradients for different parameter combinations >>> for alpha in [0.3, 0.5, 1.0]: >>> for width in [1.0, 2.0]: >>> rg_fn = surrogate.ReluGrad(alpha=alpha, width=width) >>> grads = jax.vmap(jax.grad(rg_fn))(xs) >>> ax1.plot(xs, grads, label=rf'$\alpha={alpha}, w={width}$') >>> >>> ax1.set_xlabel('Input (x)') >>> ax1.set_ylabel('Gradient') >>> ax1.set_title('ReLU Surrogate Gradients') >>> ax1.legend() >>> ax1.grid(True, alpha=0.3) >>> >>> # Show effect of width parameter >>> alpha_fixed = 0.5 >>> for width in [0.5, 1.0, 1.5, 2.0]: >>> rg_fn = surrogate.ReluGrad(alpha=alpha_fixed, width=width) >>> grads = jax.vmap(jax.grad(rg_fn))(xs) >>> ax2.plot(xs, grads, label=rf'$width={width}$') >>> >>> ax2.set_xlabel('Input (x)') >>> ax2.set_ylabel('Gradient') >>> ax2.set_title(f'Width Effect (α={alpha_fixed})') >>> ax2.legend() >>> ax2.grid(True, alpha=0.3) >>> plt.tight_layout() >>> plt.show()
(
Source code,png,hires.png,pdf)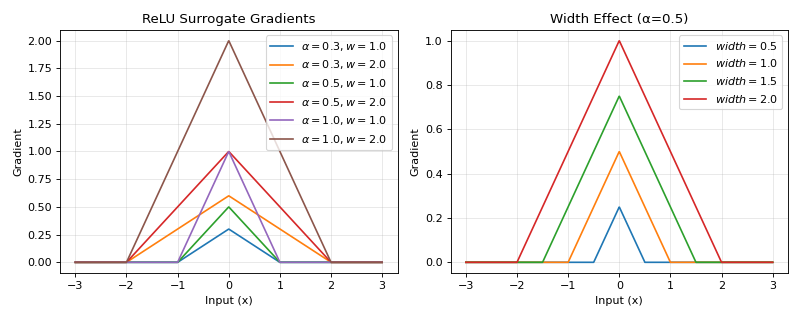
- Parameters:
Examples
>>> import jax >>> import braintools.surrogate as surrogate >>> >>> # Create ReLU gradient surrogate function >>> rg_fn = surrogate.ReluGrad(alpha=0.3, width=1.0) >>> >>> # Apply to input >>> x = jax.numpy.array([-2., -0.5, 0., 0.5, 2.]) >>> spikes = rg_fn(x) >>> print(spikes) [0. 0. 1. 1. 1.] >>> >>> # Compute gradients >>> grad_fn = jax.grad(lambda x: rg_fn(x).sum()) >>> grads = grad_fn(x) >>> print(grads) # Shows 0, 0.15, 0.3, 0.15, 0
See also
References
{kind=link}
{kind=link}