
LeakyRelu#
- class braintools.surrogate.LeakyRelu(alpha=0.1, beta=1.0)#
Judge spiking state with the Leaky ReLU function.
The Leaky ReLU surrogate gradient provides a simple piecewise linear approximation with different slopes for positive and negative inputs. This allows gradients to flow even for negative inputs, preventing the “dying ReLU” problem in spiking neural networks.
The forward function:
\[\begin{split}g(x) = \begin{cases} 1, & x \geq 0 \\ 0, & x < 0 \\ \end{cases}\end{split}\]The original function:
\[\begin{split}\begin{split}g_{origin}(x) = \begin{cases} \beta \cdot x, & x \geq 0 \\ \alpha \cdot x, & x < 0 \\ \end{cases}\end{split}\end{split}\]Backward gradient:
\[\begin{split}\begin{split}g'(x) = \begin{cases} \beta, & x \geq 0 \\ \alpha, & x < 0 \\ \end{cases}\end{split}\end{split}\]>>> import jax >>> import jax.numpy as jnp >>> import brainstate >>> import braintools.surrogate as surrogate >>> import matplotlib.pyplot as plt >>> >>> xs = jnp.linspace(-3, 3, 1000) >>> fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4)) >>> >>> # Plot gradients for different parameters >>> for alpha, beta in [(0.0, 1.0), (0.1, 1.0), (0.3, 1.0), (0.1, 0.5)]: >>> lr_fn = surrogate.LeakyRelu(alpha=alpha, beta=beta) >>> grads = jax.vmap(jax.grad(lr_fn))(xs) >>> ax1.plot(xs, grads, label=rf'$\alpha={alpha}, \beta={beta}$') >>> >>> ax1.set_xlabel('Input (x)') >>> ax1.set_ylabel('Gradient') >>> ax1.set_title('Leaky ReLU Surrogate Gradients') >>> ax1.legend() >>> ax1.grid(True, alpha=0.3) >>> ax1.set_ylim([-0.1, 1.2]) >>> >>> # Plot the original (smooth) function via surrogate_fun >>> for alpha, beta in [(0.1, 1.0), (0.3, 1.0), (0.1, 0.5)]: >>> lr_fn = surrogate.LeakyRelu(alpha=alpha, beta=beta) >>> ys = jax.vmap(lr_fn.surrogate_fun)(xs) >>> ax2.plot(xs, ys, label=rf'$\alpha={alpha}, \beta={beta}$') >>> >>> ax2.set_xlabel('Input (x)') >>> ax2.set_ylabel('Output') >>> ax2.set_title('Leaky ReLU Original Function') >>> ax2.legend() >>> ax2.grid(True, alpha=0.3) >>> plt.tight_layout() >>> plt.show()
(
Source code,png,hires.png,pdf)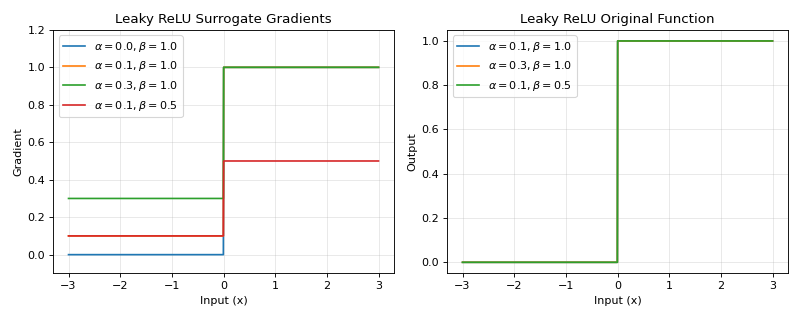
- Parameters:
Examples
>>> import jax >>> import braintools.surrogate as surrogate >>> >>> # Create Leaky ReLU surrogate function >>> lr_fn = surrogate.LeakyRelu(alpha=0.1, beta=1.0) >>> >>> # Apply to input >>> x = jax.numpy.array([-1., 0., 1.]) >>> spikes = lr_fn(x) >>> print(spikes) [0. 1. 1.] >>> >>> # Compute gradients >>> grad_fn = jax.grad(lambda x: lr_fn(x).sum()) >>> grads = grad_fn(x) >>> print(grads) [0.1 1. 1. ]
See also
leaky_reluFunctional version of Leaky ReLU surrogate gradient.
ReluGradStandard ReLU-based surrogate gradient.
PiecewiseLeakyReluPiecewise approximation with leaky ReLU.
{kind=link}
{kind=link}