
SlayerGrad#
- class braintools.surrogate.SlayerGrad(alpha=1.0)#
Judge spiking state with the slayer surrogate gradient function [1].
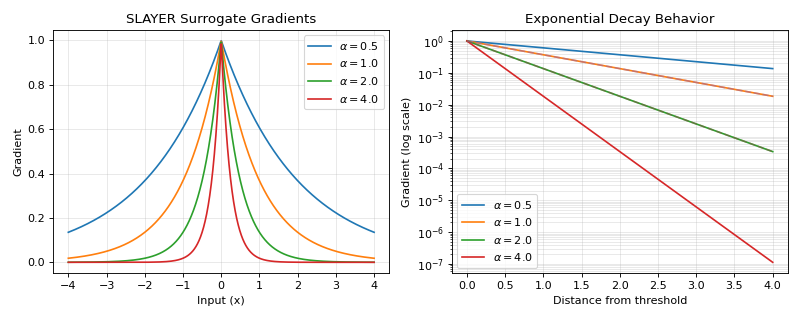
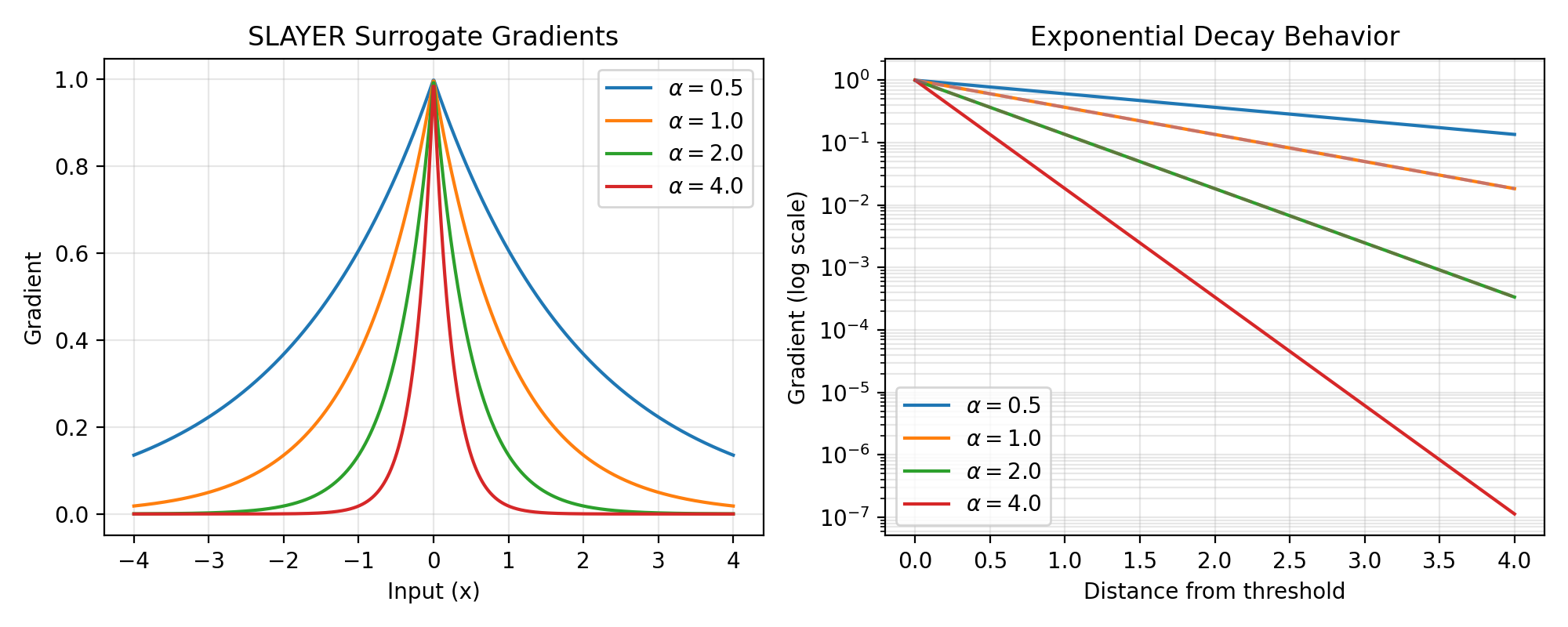
The SLAYER (Spike LAYer Error Reassignment) gradient provides an exponential decay surrogate that enables error backpropagation in spiking neural networks. It uses a Laplace-like distribution for the gradient, offering a good balance between gradient magnitude near the threshold and computational efficiency.
The forward function:
\[\begin{split}g(x) = \begin{cases} 1, & x \geq 0 \\ 0, & x < 0 \\ \end{cases}\end{split}\]Backward gradient:
\[g'(x) = \exp(-\alpha \cdot |x|)\]This creates an exponentially decaying gradient with:
Peak value of 1 at x=0
Exponential decay rate controlled by α
Symmetric profile around the threshold
>>> import jax >>> import jax.numpy as jnp >>> import brainstate >>> import braintools.surrogate as surrogate >>> import matplotlib.pyplot as plt >>> >>> xs = jnp.linspace(-4, 4, 1000) >>> fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4)) >>> >>> # Plot gradients for different alpha values >>> for alpha in [0.5, 1.0, 2.0, 4.0]: >>> sg_fn = surrogate.SlayerGrad(alpha=alpha) >>> grads = jax.vmap(jax.grad(sg_fn))(xs) >>> ax1.plot(xs, grads, label=rf'$\alpha={alpha}$') >>> >>> ax1.set_xlabel('Input (x)') >>> ax1.set_ylabel('Gradient') >>> ax1.set_title('SLAYER Surrogate Gradients') >>> ax1.legend() >>> ax1.grid(True, alpha=0.3) >>> >>> # Compare decay rates on semi-log plot >>> xs_pos = jnp.linspace(0, 4, 500) >>> for alpha in [0.5, 1.0, 2.0, 4.0]: >>> sg_fn = surrogate.SlayerGrad(alpha=alpha) >>> grads = jax.vmap(jax.grad(sg_fn))(xs_pos) >>> ax2.semilogy(xs_pos, grads, label=rf'$\alpha={alpha}$') >>> >>> # Add theoretical exponential decay lines >>> for alpha in [1.0, 2.0]: >>> theoretical = jnp.exp(-alpha * xs_pos) >>> ax2.semilogy(xs_pos, theoretical, '--', alpha=0.5) >>> >>> ax2.set_xlabel('Distance from threshold') >>> ax2.set_ylabel('Gradient (log scale)') >>> ax2.set_title('Exponential Decay Behavior') >>> ax2.legend() >>> ax2.grid(True, alpha=0.3, which="both") >>> plt.tight_layout() >>> plt.show()
(
Source code,png,hires.png,pdf)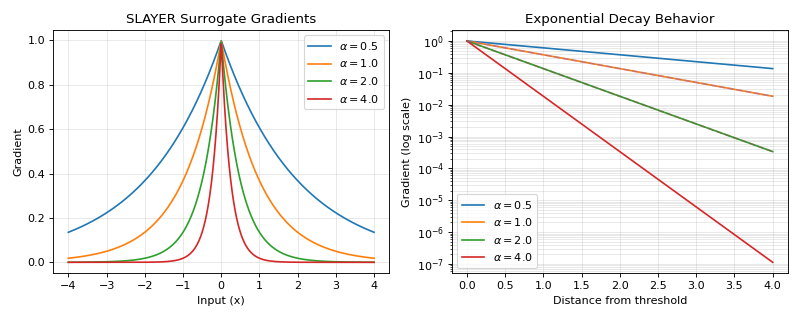
- Parameters:
alpha (float, optional) –
Parameter to control the decay rate of the gradient. Default is 1.0.
Larger α creates faster decay (sharper gradients)
Smaller α creates slower decay (wider gradients)
Decay length scale = 1/α
Examples
>>> import jax >>> import braintools.surrogate as surrogate >>> >>> # Create SLAYER gradient surrogate >>> sg_fn = surrogate.SlayerGrad(alpha=1.0) >>> >>> # Apply to input >>> x = jax.numpy.array([-2., -1., 0., 1., 2.]) >>> spikes = sg_fn(x) >>> print(spikes) [0. 0. 1. 1. 1.] >>> >>> # Compute gradients showing exponential decay >>> grad_fn = jax.grad(lambda x: sg_fn(x).sum()) >>> grads = grad_fn(x) >>> print(f"Gradients: {grads}") >>> # Shows exp(-|x|) behavior
See also
slayer_gradFunctional version of SLAYER gradient.
GaussianGradGaussian-based surrogate gradient.
InvSquareGradPower-law decay surrogate gradient.
References
{kind=link}
{kind=link}