
S2NN#
- class braintools.surrogate.S2NN(alpha=4.0, beta=1.0, epsilon=1e-08)#
Judge spiking state with the S2NN surrogate spiking function [1].
The S2NN (Single-Step Neural Network) surrogate gradient is designed for training energy-efficient single-step neural networks. It provides asymmetric gradients for positive and negative inputs, enabling better gradient flow during training.
The forward function:
\[\begin{split}g(x) = \begin{cases} 1, & x \geq 0 \\ 0, & x < 0 \\ \end{cases}\end{split}\]The original function:
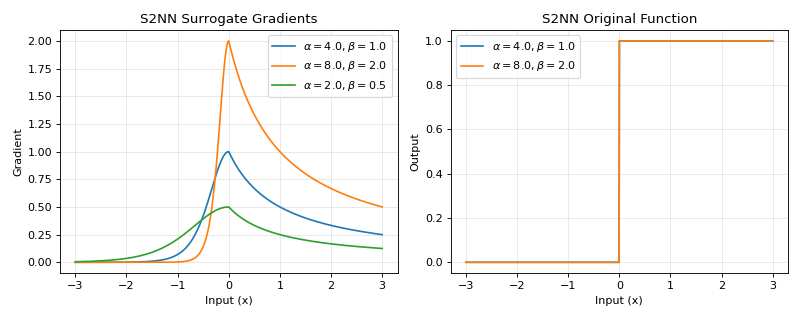
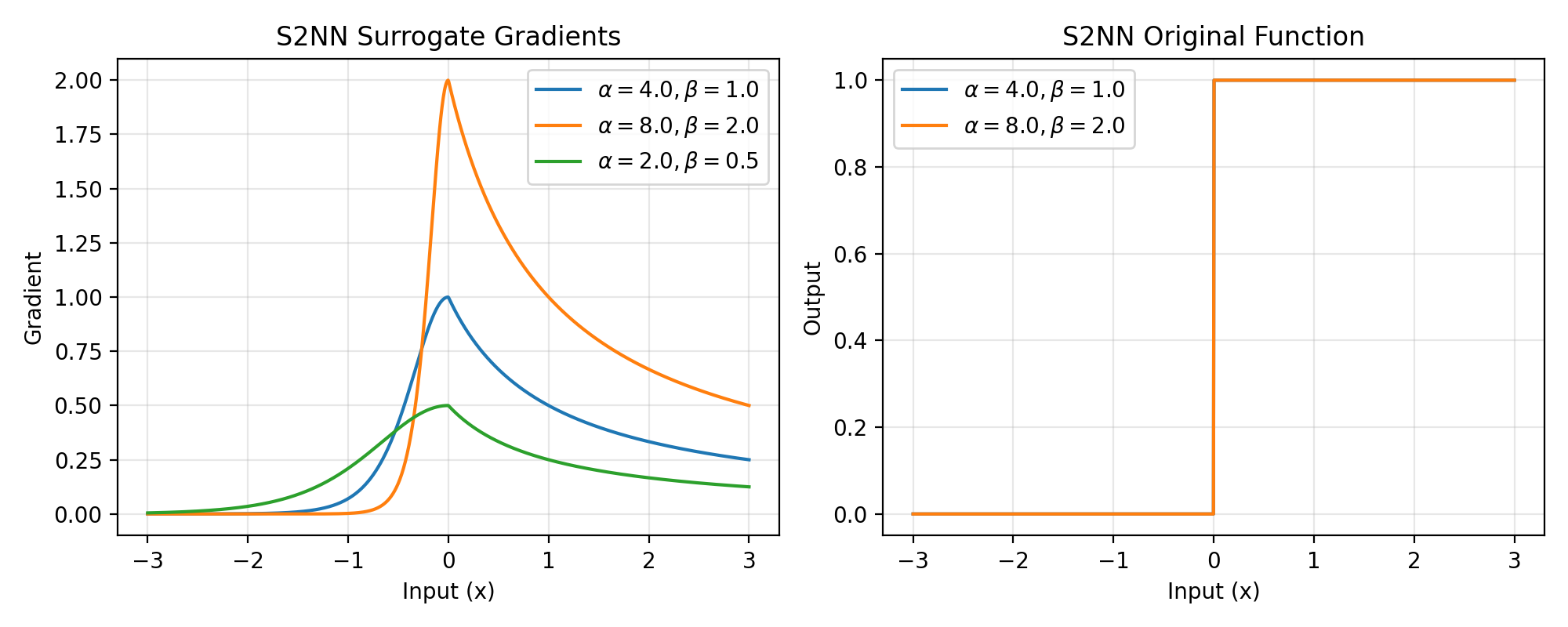
\[\begin{split} \begin{split}g_{origin}(x) = \begin{cases} \mathrm{sigmoid} (\alpha x), & x < 0 \\ \beta \ln(|x + 1|) + 0.5, & x \ge 0 \end{cases}\end{split}\end{split}\]Backward gradient:
\[\begin{split} \begin{split}g'(x) = \begin{cases} \alpha * (1 - \mathrm{sigmoid} (\alpha x)) \mathrm{sigmoid} (\alpha x), & x < 0 \\ \frac{\beta}{(x + 1)}, & x \ge 0 \end{cases}\end{split}\end{split}\]>>> import jax >>> import jax.numpy as jnp >>> import brainstate >>> import braintools.surrogate as surrogate >>> import matplotlib.pyplot as plt >>> >>> xs = jnp.linspace(-3, 3, 1000) >>> fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4)) >>> >>> # Plot gradients for different parameters >>> for alpha, beta in [(4., 1.), (8., 2.), (2., 0.5)]: >>> s2nn_fn = surrogate.S2NN(alpha=alpha, beta=beta) >>> grads = jax.vmap(jax.grad(s2nn_fn))(xs) >>> ax1.plot(xs, grads, label=rf'$\alpha={alpha}, \beta={beta}$') >>> >>> ax1.set_xlabel('Input (x)') >>> ax1.set_ylabel('Gradient') >>> ax1.set_title('S2NN Surrogate Gradients') >>> ax1.legend() >>> ax1.grid(True, alpha=0.3) >>> >>> # Plot the original (smooth) function via surrogate_fun >>> for alpha, beta in [(4., 1.), (8., 2.)]: >>> s2nn_fn = surrogate.S2NN(alpha=alpha, beta=beta) >>> ys = jax.vmap(s2nn_fn.surrogate_fun)(xs) >>> ax2.plot(xs, ys, label=rf'$\alpha={alpha}, \beta={beta}$') >>> >>> ax2.set_xlabel('Input (x)') >>> ax2.set_ylabel('Output') >>> ax2.set_title('S2NN Original Function') >>> ax2.legend() >>> ax2.grid(True, alpha=0.3) >>> plt.tight_layout() >>> plt.show()
(
Source code,png,hires.png,pdf)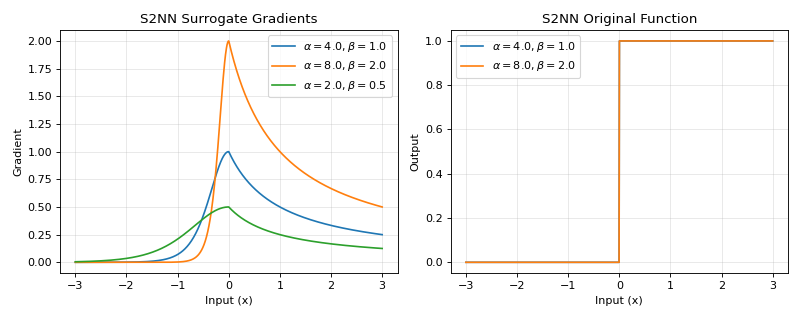
- Parameters:
alpha (float, optional) – Parameter controlling gradient when x < 0. Default is 4.0. Larger values create steeper gradients for negative inputs.
beta (float, optional) – Parameter controlling gradient when x >= 0. Default is 1.0. Larger values create stronger gradients for positive inputs.
epsilon (float, optional) – Small value to avoid numerical issues in logarithm. Default is 1e-8.
Examples
>>> import jax >>> import braintools.surrogate as surrogate >>> >>> # Create S2NN surrogate function >>> s2nn_fn = surrogate.S2NN(alpha=4.0, beta=1.0) >>> >>> # Apply to input >>> x = jax.numpy.array([-1., 0., 1.]) >>> spikes = s2nn_fn(x) >>> print(spikes) [0. 1. 1.] >>> >>> # Compute gradients >>> grad_fn = jax.grad(lambda x: s2nn_fn(x).sum()) >>> grads = grad_fn(x) >>> print(grads)
See also
s2nnFunctional version of S2NN surrogate gradient.
SigmoidSymmetric sigmoid-based surrogate gradient.
PiecewiseQuadraticQuadratic approximation surrogate gradient.
References
{kind=link}
{kind=link}