
LogTailedRelu#
- class braintools.surrogate.LogTailedRelu(alpha=0.0)#
Judge spiking state with the Log-tailed ReLU function [1].
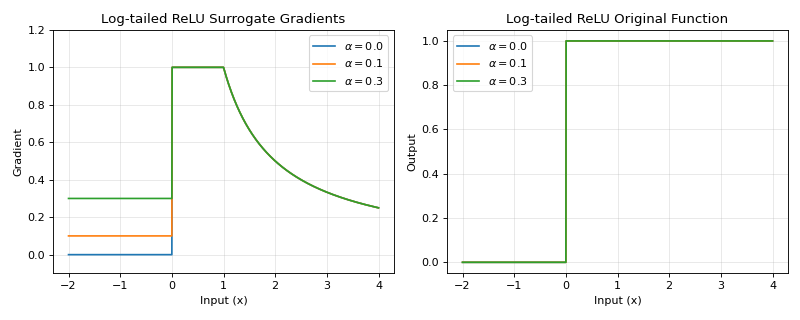
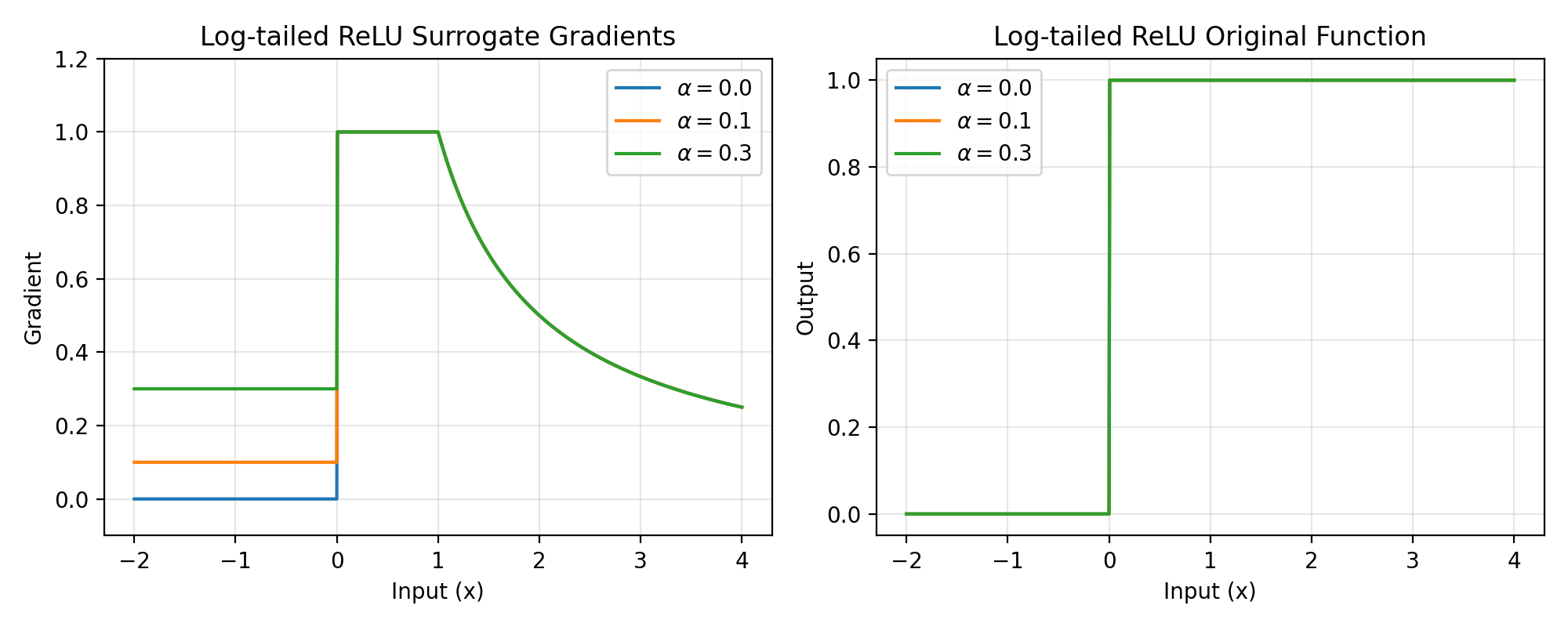
The Log-tailed ReLU surrogate gradient combines linear behavior for small positive inputs with logarithmic scaling for large inputs. This provides bounded gradients for large activations while maintaining responsiveness for smaller values, useful for handling wide dynamic ranges in spiking neural networks.
The forward function:
\[\begin{split}g(x) = \begin{cases} 1, & x \geq 0 \\ 0, & x < 0 \\ \end{cases}\end{split}\]The original function:
\[\begin{split}\begin{split}g_{origin}(x) = \begin{cases} \alpha x, & x \leq 0 \\ x, & 0 < x \leq 1 \\ 1 + \log(x), & x > 1 \\ \end{cases}\end{split}\end{split}\]The
1 +keeps the original function continuous (and \(C^1\)) at \(x = 1\), where both the linear branch and \(1 + \log(x)\) equal 1 and share the unit slope.Backward gradient:
\[\begin{split}\begin{split}g'(x) = \begin{cases} \alpha, & x \leq 0 \\ 1, & 0 < x \leq 1 \\ \frac{1}{x}, & x > 1 \\ \end{cases}\end{split}\end{split}\]>>> import jax >>> import jax.numpy as jnp >>> import brainstate >>> import braintools.surrogate as surrogate >>> import matplotlib.pyplot as plt >>> >>> xs = jnp.linspace(-2, 4, 1000) >>> fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4)) >>> >>> # Plot gradients for different alpha values >>> for alpha in [0.0, 0.1, 0.3]: >>> ltr_fn = surrogate.LogTailedRelu(alpha=alpha) >>> grads = jax.vmap(jax.grad(ltr_fn))(xs) >>> ax1.plot(xs, grads, label=rf'$\alpha={alpha}$') >>> >>> ax1.set_xlabel('Input (x)') >>> ax1.set_ylabel('Gradient') >>> ax1.set_title('Log-tailed ReLU Surrogate Gradients') >>> ax1.legend() >>> ax1.grid(True, alpha=0.3) >>> ax1.set_ylim([-0.1, 1.2]) >>> >>> # Plot the original (smooth) function via surrogate_fun >>> for alpha in [0.0, 0.1, 0.3]: >>> ltr_fn = surrogate.LogTailedRelu(alpha=alpha) >>> ys = jax.vmap(ltr_fn.surrogate_fun)(xs) >>> ax2.plot(xs, ys, label=rf'$\alpha={alpha}$') >>> >>> ax2.set_xlabel('Input (x)') >>> ax2.set_ylabel('Output') >>> ax2.set_title('Log-tailed ReLU Original Function') >>> ax2.legend() >>> ax2.grid(True, alpha=0.3) >>> plt.tight_layout() >>> plt.show()
(
Source code,png,hires.png,pdf)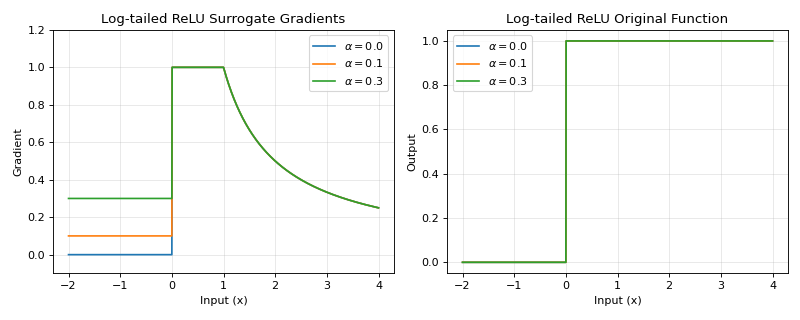
- Parameters:
alpha (float, optional) –
Parameter to control the gradient for negative inputs. Default is 0.0.
alpha = 0: No gradient for negative inputs (standard behavior)
alpha > 0: Leaky gradient for negative inputs
Examples
>>> import jax >>> import braintools.surrogate as surrogate >>> >>> # Create Log-tailed ReLU surrogate function >>> ltr_fn = surrogate.LogTailedRelu(alpha=0.1) >>> >>> # Apply to input >>> x = jax.numpy.array([-1., 0.5, 2.]) >>> spikes = ltr_fn(x) >>> print(spikes) [0. 1. 1.] >>> >>> # Compute gradients showing different regimes >>> grad_fn = jax.grad(lambda x: ltr_fn(x).sum()) >>> x_test = jax.numpy.array([-1., 0.5, 2.]) >>> grads = grad_fn(x_test) >>> print(grads) # Shows alpha, 1.0, 1/2 respectively
See also
log_tailed_reluFunctional version of Log-tailed ReLU surrogate gradient.
LeakyReluSimple leaky ReLU surrogate gradient.
ReluGradStandard ReLU-based surrogate gradient.
References
{kind=link}
{kind=link}